Modelación estadística: La regresión logística (Parte 1)
Gabriel Cavada Ch.1,2
1División de Bioestadística, Escuela de Salud Pública, Universidad de Chile.
2Facultad de Medicina, Universidad de los Andes.
Statistical modeling: Logistic regression (Part I)
La distribución de probabilidades logística
Supongamos que estamos interesados en la ocurrencia de un evento “A”, cuya probabilidad de aparición es “P”, es decir: P(A) = P y por consiguiente la probabilidad de que “A” no ocurra es P(A') = 1 – P; sin embargo, sabemos que la ocurrencia de A, y por ende su probabilidad, está relacionada con el valor que tome una variable aleatoria X, esto es P(A) = P(X ≤ x): por ejemplo, si A: una persona muere y X es la edad de la persona, es razonable pensar que P(morir) = P(Edad ≤ edad). Notar que P(A) = F(X), donde F(X) es la función de distribución de probabilidades de X. El problema fundamental es como relacionar la probabilidad de la aparición del evento “A”, con los posibles valores de la variable X.
Luego ¿Cómo hacer para que la P(A) dependa linealmente de X?; la respuesta directa a este problema sería proponer: P(A) = a + b • X, sin embargo, esta propuesta no es satisfactoria ya que P(A) = [0,1] y la función lineal puede tomar cualquier valor real. Si deseamos perseverar en la asociación lineal de la P(A) con X, debemos pensar en una transformación de P(A) que garantice que tome valores en todos los reales. Las propuestas que resuelven el problema son muchas, sin embargo, la más útil es la siguiente:
- Si consideramos el Odds del evento A, es decir
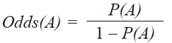 y lo evaluamos para todos los
posibles valores de P(A), obtenemos la siguiente función:
y lo evaluamos para todos los
posibles valores de P(A), obtenemos la siguiente función:
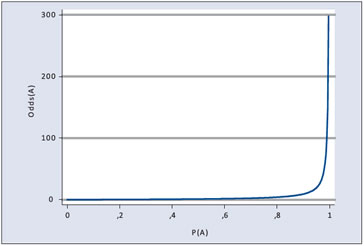
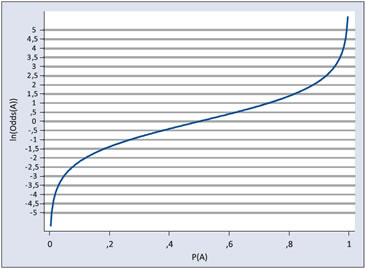
Observamos, que como es sabido que el Odds puede tomar cualquier valor real positivo, ello nos ilumina a considerar el logaritmo del Odds, ya que la función logaritmo tiene dominio en los reales positivos pero su recorrido son todos los reales, como se observa en el siguiente gráfico:
- Así entonces proponemos la relación:
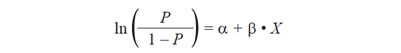
Que nos lleva a:
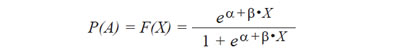
De donde deducimos que la función densidad de probabilidades es:
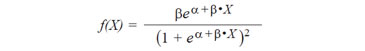
Particularmente si consideramos α = 0 y β = 1, la función densidad de probabilidades es:
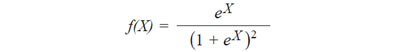
Cuyo gráfico es el siguiente:
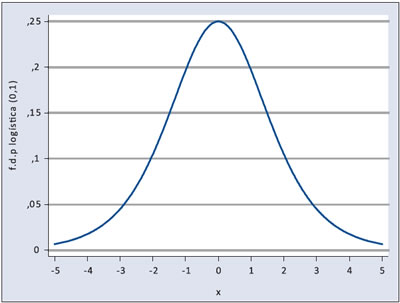
La esperanza y la varianza de la distribución logística estándar son respectivamente:

En consecuencia para la distribución logística de parámetros α y β se tiene:

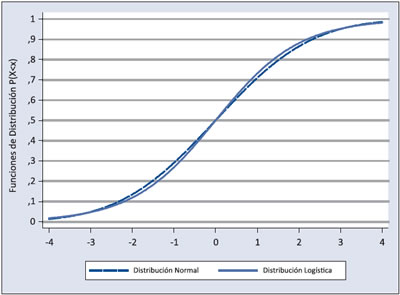
Usando estos resultados se encuentra un hecho sorprendente: la función de distribución de la logística estándar, difiere muy poco con la función de distribución de la N(0,π 2/ 3), como lo muestra el siguiente gráfico:
Para la distribución logística estándar se verifica:
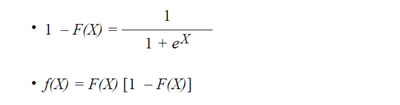
La regresión logística
Nos interesa modelar la aparición de un evento, A, explicándolo por un perfil definido como una combinación lineal de variables:
![]()
La respuesta la codificamos de la siguiente forma:

Definiendo P(Y = 1 –| |Xβ) = P(A) = π(X), es claro que la distribución de probabilidades de Y es Bernoullí con probabilidad de éxito π(X), es decir, la función de cuantía de probabilidades es:
![]()
Al asumir que π(X) = F(X) donde F(X) es la función de distribución logística evaluada en el perfil Xβ, la cuantía de probabilidades de Bernoullí se puede escribir como:
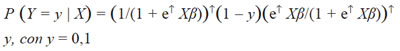
Por lo tanto, si se tiene una muestra aleatoria de “n” perfiles asociados a sus respectivas respuestas “y”, la función de verosimilitud que estima los parámetros β del modelo es:
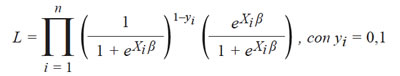
Esta función de verosimilitud corresponde al modelo logístico
de respuesta binaria. Los parámetros hay que estimarlos
mediante el método iterativo de Newton-Raphson, como
se revisó en el capítulo I.
Como se estableció anteriormente:
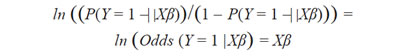
Esta relación permite comparar dos perfiles: X y X’ pues
al evaluar la expresión anterior en cada uno de estos perfiles
y luego restar estas ecuaciones se obtiene:
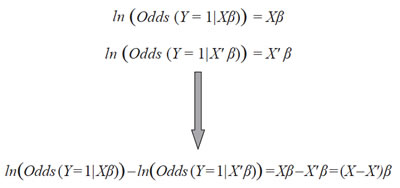
O equivalentemente:
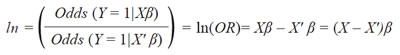
Por lo tanto, β, es el cambio del ln(OR) por cambio de perfil, de donde se deduce que:
![]()
Si X es una variable dicotómica, por ejemplo X = 1 y X = 0 denoten exposición y no exposición respectivamente, la expresión del OR es:
![]()
Cuya interpretación ya es conocida.
La novedad es que si X es una variable continua y comparamos el perfil X con el perfil X+1, la expresión que define el OR entre perfiles es:
![]()
Que representa el cambio de riesgo cuando la variable X
se incrementa en “una unidad”.
Los programas estadísticos dan la opción de reportar los
resultados en términos de coeficientes o si se desea en Odds
Ratios.
Ejemplo 1: Estimar la fuerza de la asociación en la siguiente
tabla:
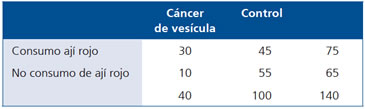

Es decir, el riesgo de estar expuesto al consumo de ají es 367% mayor en los sujetos con Cáncer de vesícula, si el consumo del ají en los controles se produjera por azar.
Ejemplo 2: Estimar la fuerza de la asociación de la glicemia con la mortalidad intrahospitalaria por IAM ajustada por género.
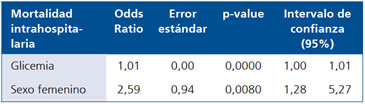
La interpretación de estos resultados es: por cada punto
de aumento en la glicemia de ingreso el riesgo de muerte
crece en 1% si en el nivel anterior la muerte se produjera por
azar, ajustando por género. O el riesgo de morir por ser mujer
es 259% mayor que si en los hombres la muerte se produjera
por azar, ajustando por glicemia.